
Distributed Databases
I’ve used a large number of operational and analytical databases throughout my career. Over the past 10 years I’ve had an increasing focus on globally distributed operational database and I’ve written this guide as a summary of what I’ve learned and hopefully it will be a useful resource for CTOs and Software Architects who need to design and build globally scalable infrastructure for their projects.
Most recently, I’ve been considering Google’s internal Spanner database and their Cloud Spanner Distributed Database offering because Snapfix was recently awarded some Google Cloud Credits. While we ultimately decided not to use Spanner, it piqued my interest in the related CockroachDB, which could be considered an Open Source implementation of the internal Google Spanner DB. I’ve been looking in detail at using CockroachDB at Snapfix.
What distributed database am I using now and what have I made extensive use of in the past?
It’s worth mentioned some of the other distributed databases that I’m using in production or have used in the past.
- MongoDB: This is a document NoSql database and I’ve used it in several past projects and am currently using it at Snapfix as a log store for our API endpoints.
- Apache CouchDB: This is similar to MongoDB. I’ve used it in the past on one large sports analytics project and I found it to be very effective as a document database and extremely user friendly.
I’ve never really used Mongo or Couch as an end-to-end standalone solution to global scale and I’ve never relied on either as a core operational database for enterprise systems. I’ve always used them as support for other operational databases or as an alternative to using JSON flat files (text files) on a HDFS file server. Using a document db gives the same flexibility but with built in search algorithms. It’s just a convenient way of organizing large scale structured flat files using a horizontally scalable document identification system (UUIDs).
-
AWS DynamoDB: This is AWS database service for distributed workloads. It’s more of a key:value store than a document store. I used DynamoDB on many smaller projects because it integrates well with other aspects of the AWS cloud stack such as API Gateway and Lambda. I also used it on one globally scalable project within the haulage industry that was IoT focused and found it to be highly scalable so long as you chose your partition keys carefully. Ultimately it proved to be clunky and difficult to maintain from a data structure perspective. It’s a good choice if you’re new to distributed systems because the documentation and explainer videos go into great detail on the trade-offs between partition keys and strategies for horizontal scaling. It’s a great half way house towards achieving competency in distributed databases and a safe choice if you’re doing your first global system and intend to leverage other AWS services.
-
FaunaDB: I’ve been following the progress of FaunaDB since 2013 but I haven’t used it in production. There’s a good HackerNoon article with Evan Weaver that explores the Fauna approach to serverless distributed database services.
-
VoltDB: Another distributed database that I’ve briefly researched and heard lots about, but I haven’t used it live.
-
CockroachDB: CockroachDB and it’s cousin, Google Spanner provide a highly capable distributed SQL database and I’ve discussed it later in this post. As mentioned above, I’m considering using it across our system as part of our Kubernetes orchestration infrastructure.
| Evan Weaver, CEO Fauna | Cockroach’s former Googlers |
|---|---|
 Previously at Twitter as employee #15, in 2018, Evan Weaver raised a $25M Series A to grow Fauna |
 Benjamin Darnell. Co-Founder & Chief Architect. Spencer Kimball. Co-Founder & CEO. Peter Mattis. Co-Founder & CTO of Cockroach Labs |
My main operational database - MySQL
MySQL is the go-to operational database I normally use. It’s not considered a distributed database, but Facebook and Google AdWords usage of MySQL would counter that general opinion. Over the past 15 years Facebook have poured billions of dollars and literally 1000+ years of engineering time into building a complex and highly functional distributed architecture on hundreds of thousands of MySQL nodes1 2. Before Google switched from MySQL to Spanner, their AdWords system ran on top of thousands of sharded MySQL nodes3.
It’s worth keeping in mind that you can go a long way towards global scale using sharded MySQL with read replicas so long as you keep in mind the transaction locking limitations of MySQL (or PostgreSQL for that matter). So long as you don’t have to significantly alter your schema or make extensive index changes during peak usage you can scale on a MySQL self hosted or cloud hosted system. There are many tips and tricks you can employ to get past these transaction locking limitations such as implementing indexes on the read-replicas, doing hot swapping of databases and so on. For example, Snapfix is a mobile centric service and we have full offline support for our mobile users. If our main operational database became unavailable for 1-5 seconds the user would remain blissfully unaware. We also use a separate pub/sub system for direct communication between users so an occasional 1-5 second interruption due to index or schema changes has no effect whatsoever on our users experiences.
However, when it comes to true global scale you are unlikely to have peaks and troughs in your load pattern and you should consider moving aspects of your operational schema out of MySQL and into a document store or relational database that’s designed to be cloud native.
Also, if you’re considering an orchestration system such as Kubernetes for your main architecture then it’s worth switching to a modern distributed database system.
Operational SQL vs NoSQL
Operational databases are required for almost every system imaginable. The operational database market is one of the largest in the software engineering space. The lions share of the market goes to the SQL based systems, with the NoSQL databases making up about 10% of the market. When MongoDB and the other NoSQL databases began hitting the market there was a lot of hype around the NoSQL aspect. At the time, I was building a semantic web system for a research institute based in Galway and I remember having a hard time accepting that a schemaless system could be used at scale and within a complex enterprise environment. When I began to use these NoSQL systems I always manually enforced a schema within my engineering teams and discouraged dynamic changes to schemas. A lot of engineers evidently went the same route and there has since emerged dedicated open source projects devoted to enforcing schemas on top of NoSQL databases.
We’ve also seen projects such as CockroachDB and Google Spanner start out as NoSQL key:value solutions and pivot back to being a core SQL solution. A big advantage of the relational approach is that the data model is embedded within the database from the onset whereas it requires manual effort or optional use of add on systems within NoSQL databases.
NoSQL shines when it comes to massive data scale. The challenge for SQL based systems is to handle that scale in the same way that schemaless NoSQL systems can. That is, allow altering of the schema while remaining fully available, through the use of non-blocking transactions or other mechanisms, as mentioned earlier in this post.
Multi-region
In any global system you’re going to have customers in more than one geographic region and it’s important to provide the same level of service to each of these customers. Due to the physical limitations of data transmission speeds, the only way to truly deliver this is to locate your systems data reasonably close to the end users physical location. In the case of Snapfix, we have users in 1000+ different cities/towns across 100+ countries. Many of these users are self-serve and their first impressions of the Snapfix system will inform their decision to convert to regular paying users of the system.
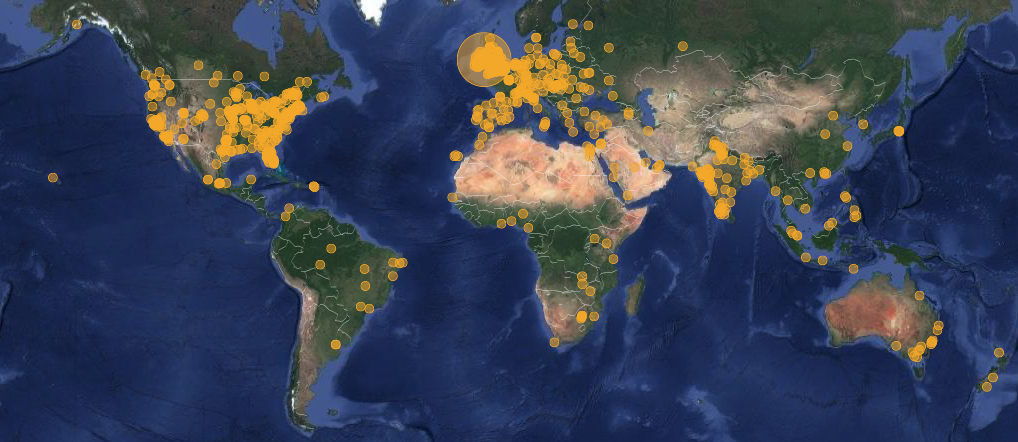
Snapfix Global Usage
When you have globally distributed active users, regional data speeds are an important consideration
These days, it’s relatively easy to attract users across the globe and it’s a major consideration when choosing a distributed database and designing a scalable schema. All of the databases already mentioned in this post have web scale data as a major design goal, but scale is not the only consideration. You have to be able to place your data in the correct region to serve targeted customers. It’s not desirable to have geographic data end points that reside in a different region than your users. There are many ways to solve this. At Snapfix, we use load-balancing that dynamically adapts to the users location and notes the round trip time for a data request. It’s becoming increasing common for this geographic positioning of data to be handled natively within distributed data services and it makes sense to consider this when choosing a service rather than having to engineer it into your system at the server level. CockroachDB, AWS DynamoDB, AWS Aurora (MySQL and PostgreSQL) and GCP Spanner all go some way to solving this issue.
Final thoughts
I hope this short post has given some insights into my choice of database for globally distributed systems. To summarize, here’s the approach I’ve taken:
- Choose a database system or service that solves as many engineering problems as possible for you. As a CTO or engineering manager you have enough on your plate, so don’t reinvent solutions to solved problems.
- Consider the proven path of using MySQL and PostgreSQL unless there’s a good reason to use a more specialized system. Remember, you can always keep your core metadata on replicated and sharded instances of MySQL or PostgreSQL on your own virtual servers (EC2) or on a service such as AWS Aurora and move the high volume, high transaction data onto a more distributed system such as Mongo or CouchDB. This can prove to be a highly cost effective way to achieve global scale.
- Choose the right time in your systems evolution to migrate fully to a relational cloud native distributed database such as CockroachDB. Pulling the gun too soon will result in unnecessary cost and may be a distraction for your engineering team when your efforts should be directed elsewhere such as the introduction of new features or the migration to micro-services.
- Remember that so-called non-distributed systems such as PostgreSQL or MySQL can be used at truly global scale so long as you can work around the transaction locking nature of these databases.
- Lastly, regardless of your choice of SQL or NoSQL, cloud native or more traditional DBs, there’s often much more to be gained by using best practices and staying up to date with the latest developments within your chosen platform, instead of switching to different systems and incurring the internal disruption this can entail. The grass may seem greener within alternative database technologies, but there’s a lot you can do to optimize your existing systems through the use of clever techniques and adherence to the approaches taken by the big data companies.